13 Module 13: Perception
You will usually find sensation and perception treated separately, as we have done in this book, but you should realize that psychologists draw this distinction for ease of explanation only. You may be tempted to think of sensation as a somewhat straightforward translation of the outside world into brain signals, and perception as a heavily brain-dependent, higher-level set of processes that have little direct contact with the original outside world. You can see the distinction is somewhat artificial from some the topics in Module 12, however. For example, a process seemingly as straightforward as detecting whether or not a stimulus is present is affected by your decision strategy. We sense brightness not in the absolute, but by comparing nearby objects to each other. So already, the brain is taking an active role in processing the neural signals that come from the outside world. You can see, however, that sensory processes do make extensive use of that information from the outside world. In perception, the brain steps to the forefront. That certainly does not mean that perception has no contact with the information from the outside world, only that the emphasis is on procedures that the brain uses to make sense out of the input.
Recall the “surviving in the wild” question asked in the Activate exercise at the beginning of Module 12. In the module, we suggested that brightness contrast, because it helps us separate objects, might be the most important visual property to help us survive. Of course, we would want to know more than simply where one object begins and another ends. Specifically, if you were trying to find food and avoid predators, you would want to know where something is, where it is going, and what it is. For example, there is a big difference between a hungry lion 30 feet in front of you sprinting out of the forest toward you, and a cute bunny 30 feet in front of you hopping into the forest away from you. So, an expanded list of processes essential for survival includes ones that allow us to locate objects and perceive their motion, and then to recognize what they are. These are the key perceptual processes, and they are quite complex, comprising several sub-processes. They include:
Localization and organization
- Perceiving distance using monocular and binocular cues
- Perceiving motion
- Grouping parts of a scene into a single object and grouping objects together
Recognition
- Bottom-up processing, such as detecting features (which you saw briefly in module 12 already)
- Using top-down processing (expectations and context) to recognize objects
This module has four sections. As we did in Module 12, we will cover perceptual topics for vision and the other sensory modes separately. Section 13.1 describes how we perceive distance and motion in vision, the main processes involved in localization. Section 13.2 covers organization in vision. It describes how we group different parts of a scene together to see distinct objects. Section 13.3 is about recognition in vision and about all three processes (localization, organization, and recognition) in the other senses. You will read about our brain’s remarkable ability reach a final perception by combining sensory input from the world with its own expectations. The section concludes with a brief discussion of sensory integration, the process through which we combine the input from the different sensory modalities into a unified experience. Section 13.4 covers attention, an important precondition for turning a sensation into a full-blown perception.
13.1. Localization in vision: Where is it and where is it going?
13.2. Organization in vision: How do the pieces fit together?
13.3. Recognition: What is it? And the Other Senses
13.4 Attention
READING WITH A PURPOSE
Remember and Understand
By reading and studying Module 13, you should be able to remember and describe:
- Basic idea of localization, organization, and recognition. (13 introduction)
- Monocular distance cues: linear perspective, interposition, relative size, relative height, texture gradient, motion parallax (13.1)
- Binocular distance cues: retinal disparity(13.1)
- Size-distance illusions (13.1)
- How we perceive motion (13.1)
- Gestalt principles of organization: similarity, proximity, figure-ground perception, good continuation, connectedness, closure, temporal segregation, common region (13.2 and 13.3)
- Bottom-up and top-down processing (13.3)
- Expectation and context effects (13.3)
- Localization in the other senses (13.3)
- Sensory integration: superior colliculus (13.3)
- Selective attention and divided attention (13.4)
- Multimode model of selective attention (13.4)
Apply
By reading and thinking about how the concepts in Module 13 apply to real life, you should be able to:
- Identify monocular distance cues in scenes and art (13.1)
- Identify Gestalt principles in real-world perceptions (13.2 and 13.3)
- Come up with your own real life examples of context and expectation effects in recognition (13.3)
- Generate your own real life examples of divided and selective attention tasks (13.4)
Analyze, Evaluate, or Create
By reading and thinking about Module 13, participating in classroom activities, and completing out-of-class assignments, you should be able to:
- Draw a picture that uses monocular cues to give the appearance of distance (13.1)
- Explain how distance cues lead to size-distance illusions that were not covered in the text (13.1)
13.1. Localization in Vision: Where Is It and Where Is It Going?
Activate
- Look out of a window that has a good long-distance view. How does the appearance of close objects compare to the appearance of far away objects? List as many differences as you can.
In order to visually perceive where something is, you have to perceive how far away it is and in which direction and at what speed it’s moving. Localization, then, is a matter of perceiving both distance and motion.
Distance Perception
How do you see distance? The naïve understanding of vision is that distance is something that is directly perceived. Some objects are simply farther away than others, and the eye must somehow record that difference. The problem with this idea is that the three-dimensional world needs to be projected onto a two-dimensional retina at the back of the eye. The loss of that third dimension means that distance cannot be directly “recorded” by the eye. For a simple demonstration of this fact, try looking at a car that is far away from you. The car in your visual field appears very small. Then imagine looking at a toy car sitting on a table near to you. Both cars might project the same-size image to your retina, so your brain must be able to figure out the difference in their actual sizes and their distances. Although it happens with no conscious effort on your part, it is actually a complicated task.
Monocular Cues
The brain reconstructs distance by using information beyond the image of the single object projected on the retina. There are a number of cues to distance that the brain uses to do this; they are divided into binocular cues and monocular cues. Binocular cues work because we have two eyes; monocular cues need a single eye only.
Common monocular cues include the following:
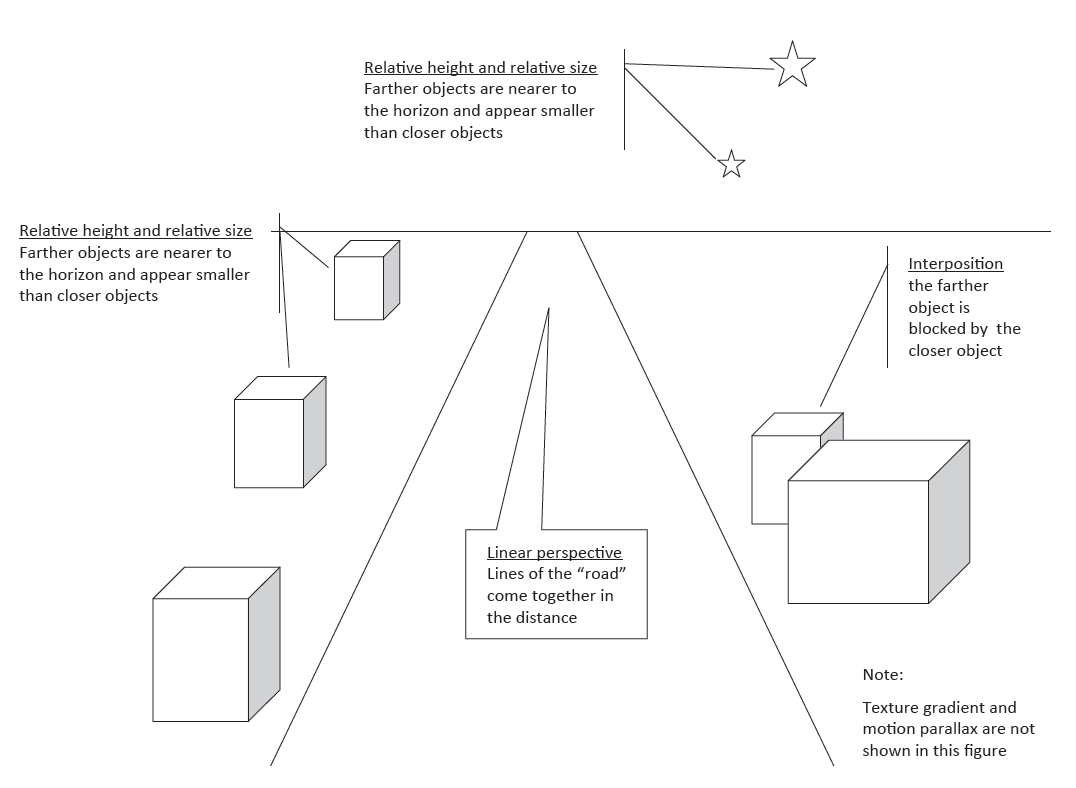
- Linear perspective. As you look at lines over distance, they appear to converge, or come together. This convergence of lines is called linear perspective.
- Interposition. Although the term “interposition” is probably new for you, the concept is extremely simple. Sometimes, when you are looking at two objects at different distances, you can judge their relative distances because the closer object partially blocks your view of the farther object. So when parents complain that they cannot see the television because a child is in the way (the “dad joke” way to say it is that you make a better door than a window), they are complaining about interposition.
- Relative size. If two objects that are the same size are different distances away from you, the farther object will appear smaller than the closer object.
- Relative height. Objects that are farther away appear to be nearer to the horizon than closer objects. This means that above the horizon, the far away object appears lower than the close object; below the horizon, the far away object appears higher than the close object.
- Texture gradient. A gradient is a change in something. The apparent change in texture, or the texture gradient, is a cue that you are looking at something over distance. For example, imagine standing at the edge of a long field of grass. Very close to you, the texture appears very rough; you can see individual blades of grass and many details of the surface. As you move your gaze farther away, the field begins to look smoother; you cannot see as many details, and you cannot see the individual blades of grass. Very far away, the field looks like a smooth, green surface. That change in apparent texture, from rough to smooth, is the texture gradient that tells you that you are looking at a change in distance.
- Motion parallax. Motion parallax is the one monocular cue that requires you to be in motion to use it. If you are moving, riding along in a car, for example, the world outside appears to move in the opposite direction of your motion. The speed with which the world appears to move is a cue to how far away an object is. Houses that appear to move slowly will be perceived as farther away from you, while parked cars that appear to move very fast will be perceived as very near to you.
localization: the process of perceiving where something is – how far away and in which direction – and whether or not it is moving
monocular cues: distance cues that require the use of a single eye only. They include linear perspective, interposition, relative size, relative height, texture gradient, and motion parallax.
Binocular Cues
Did you ever wonder why animals have two eyes? One of the main reasons is that they provide binocular cues to help us to perceive distance. One major binocular distance cue is retinal disparity. Because your eyes are a few inches apart from each other, when you focus both eyes on a single object, each eye sees the object from a slightly different angle. Try this little demonstration: take your left index finger and point it at the ceiling, with the first knuckle touching the tip of your nose. Then alternate looking at the finger with your left eye and right eye. You will be able to see your fingernail with your left eye, but not with your right eye. In addition, it appears that your finger is jumping back and forth each time you switch eyes. Now hold your index finger in front of you with your arm fully extended. Again, alternate looking with your left and right eyes. You can tell that each eye has a different angle of the finger, but the difference is much less pronounced. Your finger still appears to jump back and forth, but much less than it did when it was touching your nose. You have just demonstrated that retinal disparity is reduced when the object is farther away. Quite simply, the greater the difference in view between the two eyes—that is, the more retinal disparity there is—the closer the object is to you.
The Viewmaster, a toy that has been around for more than 70 years, uses the principle of retinal disparity to give the illusion of distance. Each picture that you see when looking into the Viewmaster is composed of two slightly different versions of the picture, one projected to each eye. The different versions are interpreted as retinal disparity, and as a result, the scene appears to be three-dimensional.

binocular cues: distance cues that require the use of two eyes
retinal disparity: a binocular cue; the difference between the image projected to the left and right retina is a cue to how far away some object is
Because distance and size are not directly perceived, but rather figured out from cues, we might be wrong occasionally. When we are, we fall victim to one of the many size-distance illusions that affect us. Although illusions are, by definition, errors, they result from the operation of the same perceptual processes that ordinarily lead us to correct judgments. For example, look at the diagram below on the left. It looks like a woman being chased down a long hall by a taller monster. The two characters are the same size on the page, however. How are we tricked into seeing the monster as taller than the woman? Well, two distance cues, linear perspective and relative height, tell us that the woman is close and the monster far away. A third distance cue, relative size, leads us to the error, though. If the monster is the same size as the woman in real life, he should look smaller when he is judged to be farther away. His appearance is not smaller like we would expect, however. We cannot judge that he is closer because of the cues suggesting he is far away, so the only alternative is to conclude that the monster is actually larger than the woman.
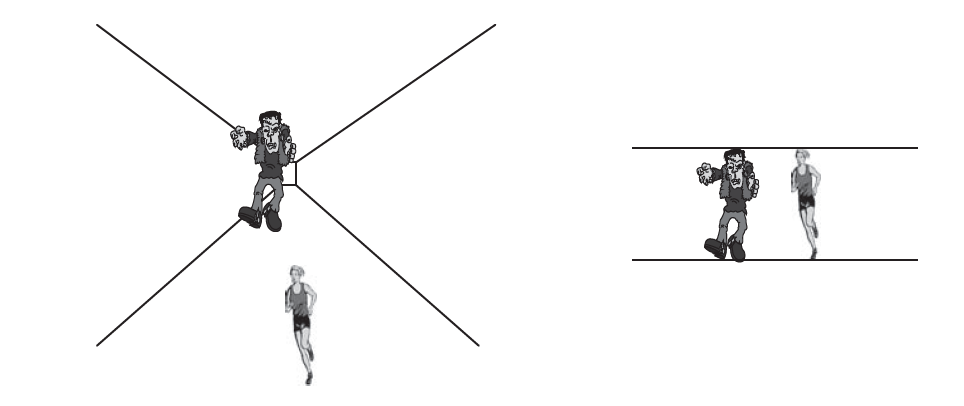
We are not saying that this conclusion is a conscious decision. You do not consciously decide that something is far away, close, large, or small. Your brain uses the distance cues and draws the conclusion unconsciously; to your conscious mind, it feels as if the distance and size are perceived directly, though, despite all of the work that goes into it.
Motion Perception
When perceiving distance, the image that is projected to your retina is ambiguous. For example, a small retinal image can mean you are looking at a small, close object or a large, far away object. You needed extra distance cues to help sort out the ambiguity. Perceiving motion also involves ambiguous retinal images that require additional cues to resolve. The problem is more difficult, however, because often the retinal image is completely misleading. It seems reasonable to suppose that moving objects would cast a moving image on your retina, and stationary objects would cast a stationary image. This is not typically the case, however. If you are watching the moving object, the image will be fairly stationary, as it is maintained in the fovea in the middle of your retina (your eyes will track, or move along with the object to do this). On the other hand, if you move your eyes away from a stationary object to look at something else, the image will zip across your retina. In both cases, you are likely to perceive the motion correctly, however.
Two key cues that allow us to detect motion are contrast and eye-head movements. Contrast in general is an important concept for perception; you already saw how brightness contrast is enhanced in visual sensation. For the perception of motion, we are interested in the contrast in movement between different elements of a scene. When you move your eyes around, the whole world around you appears to move. You do not perceive that as motion, however, because everything is “moving” at the same rate and direction. It is only when some objects in your view move and others do not that you perceive motion. This is an extremely effective cue that tells us that part of the scene is moving (Wallach et al., 1985). Researchers have also shown that neurons in the temporal lobes are sensitive to this kind of contrast (Tanaka et al., 1993).
The second cue for motion perception is eye and head movements (Epstein & Hanson, 1977; Stork & Musseler, 2004). Information about eye movements is sent from the muscles of the eyes—another example of proprioception—and from the motor commands from the brain to the visual processing areas, such as the visual cortex. Both of these sources of information can provide cues that the eyes are tracking a moving object (O’Regan & Noe, 2001).
Debrief
- Draw your own picture (or pictures) illustrating the monocular distance cues.
- Can you use the information on size-distance illusions to explain why the moon looks larger when it is on the horizon than when it is higher in the sky?
13.2. Organization in Vision: How Do the Pieces Fit Together?
Activate
- Look at the room around you. What are the separate objects that you see? Which aspects of the scene are the most important for allowing you to see the different objects in your view?
Localization is certainly important for turning a sensation into a meaningful perception, but it is just the beginning. The next key step is to begin to assemble the different pieces of a visual sensation into unified whole. Only then, can the table be set for a final recognition. The processes through which we create this unified whole are referred to as organization, and the main ones are referred to as Gestalt principles.
Grouping Using Gestalt Principles
The most important strategies that the brain uses to organize parts of a scene into distinct objects and to group objects together were discovered by the group of German psychologists called Gestalt psychologists; they were introduced in Unit 2 in the discussion of problem-solving. The Gestalt psychologists were interested in how human perception can construct a single, coherent, whole perception from the individual parts. They proposed that the brain must augment the physical input (the parts) by imposing its own organizing principles; it is from the Gestalt psychologists that we get the common idea that the whole is greater than the sum of its parts. Their chief concern with perception was how we decide which parts of a possible perception should be grouped together into objects or sets of objects.
You should keep these two related kinds of grouping in mind: grouping separate elements together into a single object and grouping different objects together into sets. We can use the Gestalt principles to describe both kinds of groupings. The Gestalt psychologists identified many principles, the best-known being the following. It is important to note that a given scene might require the application of more than one Gestalt principle.
Similarity, Proximity, and Connectedness
Objects will tend to be grouped together when they are similar to each other (similarity), when they are close to each other (proximity), or when they are physically connected to each other connectedness.
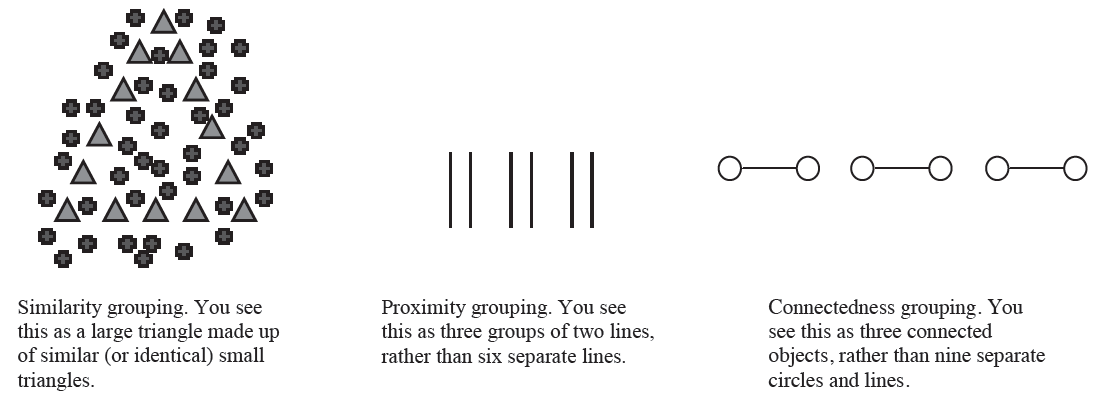
Sometimes the different Gestalt principles lead us to make the same grouping, sometimes not. If you have ever watched a soccer game between two teams of six-year-olds, you can use different groupings based on similarity and proximity to help make sense of the action. All of the children with the same-colored shirt are on the same team; in other words, a similarity grouping helps you figure out which players you should be cheering for. And you can tell where the ball is on the field if you temporarily lose sight of it because most of the children tend to cluster around the ball; in those situations, you are using a grouping based on proximity (in case you have never had the pleasure to see for yourself, six-year-olds have not figured out that sometimes, you are not supposed to be next to the ball).
Figure-Ground Perception
The observation that multiple groupings are possible points out the need for another Gestalt principle, called figure-ground perception. According to this principle, we can shift our attention throughout a scene to pick one section as the object of interest, or figure, and relegate the rest of the visual information to the background, or ground. At the soccer field, you might perceive the group of children who are bunched around the ball as the figure and the rest of the children, the coaches (who are also on the field), the referee, and the field itself as part of the background. If you are paying attention to one specific kid chatting with a friend from the opposing team, they are the figure, and everything else is the background. The best-known illustrations of our ability to switch figure and ground are reversible figures, a figure that can have two completely different interpretations by switching figure and ground. Even when the objects themselves are unambiguous, we may shift our figure-ground perception at will to make one part the figure and the rest the background.

Good Continuation
Grouping by good continuation is a principle that helps us to see a pattern in the simplest input. We have a preference for grouping that will allow us to see a smooth, continuous form. So you are more likely to group (or see) the dots in the diagram below as two intersecting curved lines, rather than four separate segments.
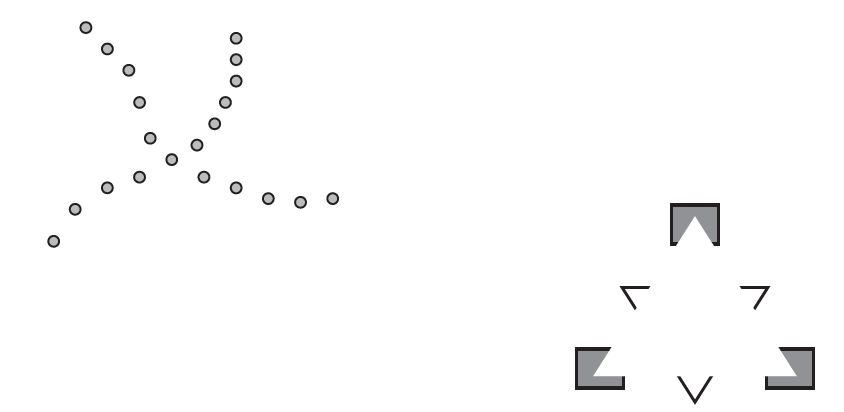
Closure
In our quest to perceive a coherent, whole perception (a Gestalt), we may have to add to what is really there. In other words, when other Gestalt principles strongly suggest a certain grouping but the picture is incomplete, we may use closure to fill in the missing gaps. For example, the similarity principle suggests that the three simple angles in the figure above should be grouped together to form a triangle that is underneath a second triangle formed by the rectangles with the angles missing. That top triangle is not really in the picture, however. Closure allows us to complete the triangle, though, and we see the whole shape.
This is probably a good time to remind you that even though most of the examples have focused on how we group separate objects of a scene into sets, they also can be used to group different parts into a single object, as in the closure example.
Recent researchers have added to the Gestalt grouping principles. For example, elements that appear at the same time tend to be grouped together, a principle known as temporal segregation (Singer, 2000). To use another soccer example, the players who run onto the field together are perceived to belong to the same team. Finally, elements that are bound into a common region tend to be grouped together (Palmer, 1992). Many soccer parks in our town have several fields on them. The children who are confined to one field constitute a single grouping, a game.
It is also worth noting that recent research results have found evidence in the brain for some of the original Gestalt principles. For example, there appear to be figure-ground cells in the cortex that respond to one figure-ground grouping and not its reversal, suggesting that “figure” is a feature coded by the visual system (Baylis and Driver, 2001).
closure: a Gestalt principle that says that we tend to fill in missing perceptual information
common region: a perceptual principle that says that objects that are found in the same space tend to be grouped together
connectedness: a Gestalt principle that says that objects that are connected to one another will be grouped together
figure-ground perception: a Gestalt principle that says that we can shift our attention to pick out one part of a scene and to shift the rest to the background
Gestalt principles: a set of principles that describe how be organize sensory input, mostly by grouping or separating individual parts; they were originally discovered by Gestalt psychologists in the early 20th century
good continuation: a Gestalt principle that says that we have a preference for seeing patterns that are smooth continuous forms
proximity: a Gestalt principle that says that objects that are close to one another will be grouped together
similarity: a Gestalt principle that says that objects that are similar to one another will be grouped together
temporal segregation: a perceptual principle that says that objects that appear at the same time tend to be grouped together
Debrief
- Come up with some visual examples of the Gestalt principles of similarity, proximity, figure-ground perception, good continuation, and closure.
13.3. Recognition: What Is It?
Activate
- Did you ever notice that it takes you an extra moment to recognize a familiar person in an unfamiliar location (for example, your psychology professor in the grocery store)? Why do you think that is?
- Have you ever walked into a dark room when you were (already) frightened, and mistaken a harmless object, such as a stuffed animal, for something much more sinister and dangerous? Why do you think that happens?
We have just crossed over a fuzzy and somewhat arbitrary line. Although the ideas we have talked about already are important for localizing and organizing, they also contribute mightily to final recognition. For example, when you group the eleven children on one side of the soccer field together, it is only a small step beyond that for you to recognize them as The Blizzards (the team’s name). Nevertheless, it seems useful to separate the processes as we have done, as is typical within psychology, as long as you realize that these earlier processes contribute to recognition.
Think back even earlier, to the visual sensation processes we talked about in Module 12, such as detection of brightness contrast, features, and color. Add to those the localization processes of distance and motion perception. All of these processes help you to recognize objects. In some ways, these earlier parts of the overall recognition task are like putting together a jigsaw puzzle. Small regions of the puzzle are assembled out of individual pieces. Then, those small regions are combined into larger sections, which are assembled into the final completed puzzle. In the same way, our perceptual system builds up to a final recognition from simple features, such as colors and lines, through more and more complex features, such as angles, shapes and surfaces, all the way up to a complete scene, a soccer game. This kind of perceptual processing, in which a final recognition is “built up” from basic features is called bottom-up processing. It begins “out in the world,” with the basic properties of the objects to be perceived.
We can push the puzzle analogy a bit further to introduce you to the other major type of processing that takes place during recognition, Think about the procedure that many people use when they assemble jigsaw puzzles. They spread out the pieces on the table in front of them and prop up the cover of the puzzle box, so they can see what the completed puzzle is supposed to look like. That box cover tells them which pieces belong in which areas. For example, the brown pieces might be part of a horse’s body, which belongs on the lower left side of the puzzle, according to the picture on the box. We have a set of mental processes in perception that correspond to the puzzle box cover. It is called top-down processing and it consists of expectation effects and context effects (the Gestalt principles are essentially top-down processes, too, as they are organizing strategies imposed by the brain). Just like referring to a picture on a box when assembling a jigsaw puzzle, the top-down processes help you predict what will go where in your final perception, or recognition. Even better, they help you to direct your attention to the appropriate areas so that you can recognize objects and scenes very quickly.
The combination of bottom-up and top-down processes typically makes final recognition efficient and effortless. We have already spent some time on the bottom-up processes, so let’s turn to top-down ones. First consider how expectation effects influence recognition. Suppose you worked your way through high school as a kids’ soccer referee. Through this experience you have come to expect certain things. For example, at the beginning of each half and after goals, the teams assemble on their respective halves of the field. After a goal is scored, then, you have an expectation. In other words, you know where to look if you want to find the different teams. This is the basic idea behind the expectation effect. Because you know what to look for, it becomes easy for you to find it. Although this seems obvious and perhaps uninteresting, it is important because these top-down processes are extremely powerful.
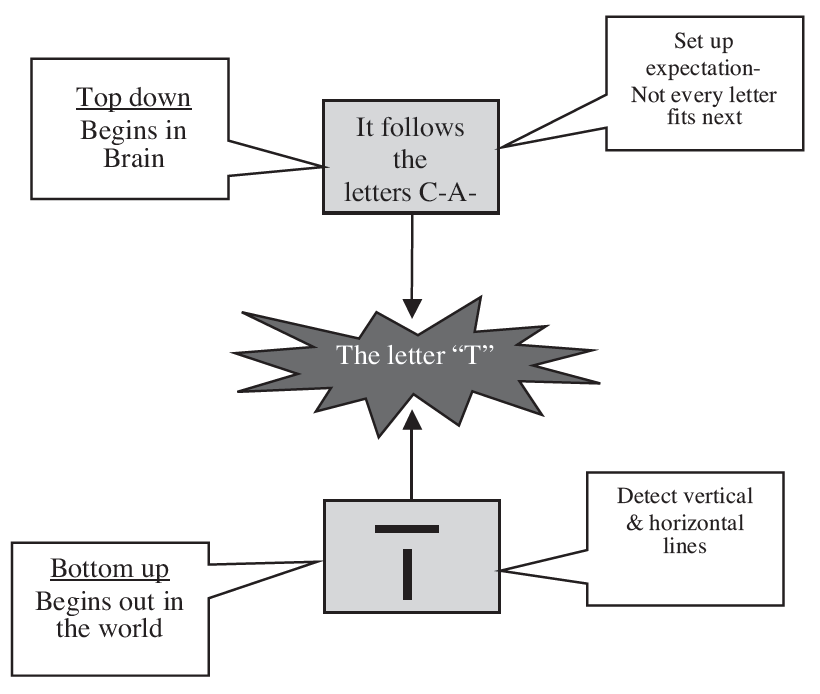
A simple example of the interplay between top-down and bottom-up processing will help you to see how they work together to give us such an effective recognition system. Imagine that you are trying to recognize a printed letter on a page. Bottom-up processing, such as feature detection, sends the signal that you are looking at a vertical line and a horizontal line. The fact that the letter follows two other letters, C and A, sets up an expectation. If the three letters are to form a word, only a few letters, such as B, D, M, N, P, and T will fit. Final recognition of the letter “meets in the middle,” as the powerful bottom-up effects of detecting the features and top-down effects of expecting certain letters allow you to instantly see it as the letter T. Although most real-life experiences of recognizing objects are more complicated, the same basic “meeting” of top-down and bottom-up processes occurs.
Ordinarily, the top-down processes help you to perceive the world accurately and instantly. For example, given your expectation during a soccer game, it only takes a quick glance to find the different teams after a goal. Your expectation, however, can be powerful enough to change your perception. For example, in 2003, Las Vegas magician and tiger trainer Roy Horn, of the team Siegfried and Roy was attacked, dragged offstage by his neck, mauled, and nearly killed by a 600-pound tiger during his act (Roy actually died in 2020 from COVID-19). Roy’s partner, Siegfried, reported soon after the attack that the tiger was trying to help Roy during a moment of confusion (Roy had just tripped). Animal behavior experts disagreed. They noted that the tiger went for Roy’s neck, the key killing behavior that tigers use on their prey, an interpretation shared years later by one of the team’s animal trainers (Nash, 2019). Because of their different expectations—Siegfried thought about the tiger as a partner in the act, even a friend, while the animal behavior experts thought about the tiger as an instinctual killer—they perceived the same behavior very differently. You will be able to find many similar examples of someone’s expectation changing the way that he or she perceives something.
The second key type of top-down process is context effects, in which the objects or information surrounding the target object affect perception. When you see your psychology professor walk into class every day, it is easy to recognize him or her in the familiar context of a classroom. But have you ever run into a professor (or other teacher) in an unexpected location, such as a grocery store, or even a bar? If so, you might not have recognized him or her at first because of the unusual context. As with expectation effects, context effects can be powerful enough to change your actual recognition. The middle character in the example below can look like the letter B or the number 13, depending on the context in which you find it (Biderman, Shir, & Mudrik (2020). And again, think of the Siegfried and Roy example. A 600-pound tiger pouncing on a man, grabbing him by the neck, and dragging him to another location would certainly not be perceived as the tiger helping the man if it occurred in the context of an expedition in the wilderness of India. You should also be able to see that context and expectation are related; often it is the context that helps set up an expectation.
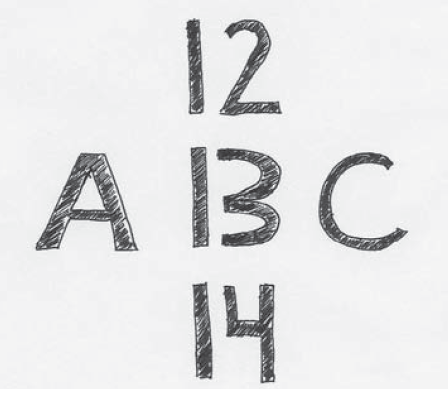
bottom-up processing: perceptual processing that leads to recognition by beginning with individual features in the world and “building up” a final recognition
top-down processing: perceptual processing that leads to recognition by beginning with the brain, which directs (via expectation and context effects) how recognition proceeds
expectation effects: a top-down processing effect in which having an expectation leads an individual to perceive some stimulus to be consistent with the expectation
context effects: a top-down processing effect in which the information that surrounds a target stimulus leads an individual to perceive the stimulus in a way that fits into the context
Localization, Organization, and Recognition in the other senses
Many of the principles that we identified for vision apply to the other senses too, so it seems unnecessary to repeat them in great detail. Basically, regardless of the sensory modality, you need to localize, organize, and recognize. Top-down processing and similar organization principles affect hearing, touch, taste, and smell. Let us spend a few minutes discovering how these ideas apply to the other senses, then. At the end of the section, we will talk about how our brain takes the input from the different senses and assembles it into a single perceptual experience.
Hearing
You will recall that the outer, middle, and inner ear translate air vibrations into bone vibrations via the tympanic membrane, hammer, anvil, and stirrup, and then into neural signals via the oval window and hair cells (in the cochlea). The intensity of the vibrations is translated into loudness, and the speed, or frequency of the vibrations is translated into pitch. This is a far cry from the rich detailed auditory world in which we live. The basic sensory processes as we described them in Module 12 explain how we detect the beeps of a hearing test in an audiologist’s office, but how do we get from there to hearing complex sounds, such as speech, music, and city noise?
First, there are relatively few pure tones, made up of a single frequency, in the natural world. Complex sounds, however, can be broken down into their component frequencies, so the auditory system has a set of processes that are analogous to feature detection from vision.
Of course, localization, organization, and recognition are essential for the perception of sounds. Localization takes place through a process similar to the binocular cues from vision. When a sound comes from one side of the body, it reaches the corresponding ear sooner and is louder to that ear (Gaik, 1993; Middlebrook et al., 1989). The brain is extremely sensitive to these tiny time and loudness differences and uses them to locate the source of the sound. There are also hearing analogs of some of the monocular cues to distance. For example, close objects make louder and clearer sounds than far away objects
For the organization of sounds, Gestalt principles for grouping apply as well to hearing as they do to vision. In fact, some of the best examples of figure-ground perception are auditory. Any time you try to listen to one message, such as your friend whispering in your ear, while ignoring another, such as a boring lecture, you are selecting one as the figure and the other as the background. As soon as your professor calls your name to ask you to answer a question, you can instantly switch and make the former background into the figure. A strategic pause in a string of sounds can lead to different groupings based on proximity or connectedness in time, as in “What is this thing called love?” versus “What is this thing called, love?” Good continuation (as well as figure-ground perception) enhances our ability to follow a melody during a complex musical recording (Deutsch & Feroe, 1981). Similarity helps us to separate sounds that occur at the same time. For example, if a complex sound, such as a musical chord, contains a badly mistuned element, we may hear two separate sounds. If everything is in tune, we hear a single integrated sound (Alain, Arnott, & Picton, 2001).
Closure, too, works in hearing, as we can often hear a complete sound, such as a word, even if a small section is missing. For example, if a sound is interrupted by bursts of noise, we will hear the tone as constant (Kluender & Jenison, 1992; Warren, 1984)
The top-down processes for recognition are also extremely important in hearing. Many times, we hear what we expect to hear. For example, consider song lyrics. Sometimes, you may be unable to understand the lyrics of a song until you read them. Once you have the expectation that comes from reading the lyrics, you can hear them from then on. In general, our experiences leave us with a wealth of knowledge about sounds, and we use this knowledge to help us recognize (Bregman, 1990). Of course, one key source of both context and expectation is information from other sensory modes, such as vision. For example, the sight of a violin in a companion’s hands would help you to recognize the awful screeching sound as an attempt at music rather than a sick cat.
Taste and Smell
Although we certainly have to locate odors, localizing is an unnecessary process for taste. Localization for olfaction occurs largely through sniffing and detecting increasing concentrations of the odor, essentially searching for JND’s. Some of the principles of organization and recognition apply to both taste and smell. You can certainly use Gestalt principles, such as similarity to separate different odors and different tastes.
If you do not believe that top-down processing affects the sense of taste, ask yourself this: why do food manufacturers use artificial colors? Expectation effects have a remarkable and surprising effect on taste. Pepsi once released a clear version of its cola, called Crystal Pepsi; it was a spectacular failure (We once found an online petition to compel Pepsico to bring back Crystal Pepsi; it was signed by 79 people; the “Save Spongebob Squarepants” petition on the same site was signed by 25,000. And we didn’t even know Spongebob was in danger).
People really do think that food tastes better if top-down processing leads them to expect it. Researchers have found that if a restaurant offers a food with a descriptive name, such as Legendary Chocolate Mousse Pie, it sets up an expectation in customers that leads them to judge it to be higher quality (Wansink, Painter, & van Ittersum, 2001). Also, the fact that odor is necessary for proper tasting indicates that olfaction can function as the source of expectation effects for taste.
Touch
Some of the Gestalt principles even apply to touch. Similarity and proximity are likely important ways for us to judge whether pressure, temperature, and pain sensations result from the same or different stimuli. For example, sometimes, when people have a bad fever, they get a bad headache, as well as pain in their knees, lower back, and other joints. It can take them several hours, or even days, to connect these different sensations as part of the same illness because they are in such different locations, and they usually strike at different times during the course of the illness.
After a sensory organ has received constant input for a short time, the sensation fades away and eventually disappears. It is called sensory adaptation, and it applies to all of the senses. It even applies to vision, but you never experience it because your eyes are continually moving, ensuring a constantly changing sensation. Probably the most obvious example is from olfaction. A few minutes after entering a room with a distinctive odor, you adapt to it and no longer notice it. Sensory adaptation is also obvious in touch. If you wear glasses, you rarely notice them touching the bridge of your nose. Also, moments after getting dressed, you no longer feel the elastic waistband of your underwear. If, however, we draw your attention to it, as we just did, you are likely to be able to feel it again. This can be seen as an example of figure-ground perception; we can reverse sensory adaptation and turn a former background sensation into “figure.”
Finally, there is little doubt that top-down processing can be quite important for touch. For example, the very same sensation may be experienced as an affectionate caress or an annoying rub, depending on the context in which it occurs. Even pain can be affected by top-down processing. You probably recall that our sensation of pain comes from nociceptors that respond to potentially damaging stimuli. Our brains can override these pain signals through motivation, context or attention. For example, the motivation-decision model shows that if there is something that we judge more important than pain, our brain can suppress the signals from the nociceptors, thus reducing our perception of the pain (Fields, 2006).
Putting a Perception all Together: Sensory Integration
In real life, perception is not so neatly separable into different sensory processes as Modules 12 and 13 have implied. Very few, if any, experiences impact a single sensory mode only. Instead, we experience a coherent event, in which the input from the separate senses is integrated. This is an obvious point when you are perceiving something, but it is hard to keep in mind when each sensory modality is discussed separately in a textbook. Even within a single sense, the results of many separate processes must be integrated to give us the experience of a single perception.
We have given you an idea of one way that the different modes interact by suggesting how one sense may function as a source of expectation or context effects for another sense. In general, we often experience multisensory enhancement, in which the contributions of individual sensory modes are combined and result in a perception that is, in a way, stronger than the contributions of each sense individually (Lachs, 2020).
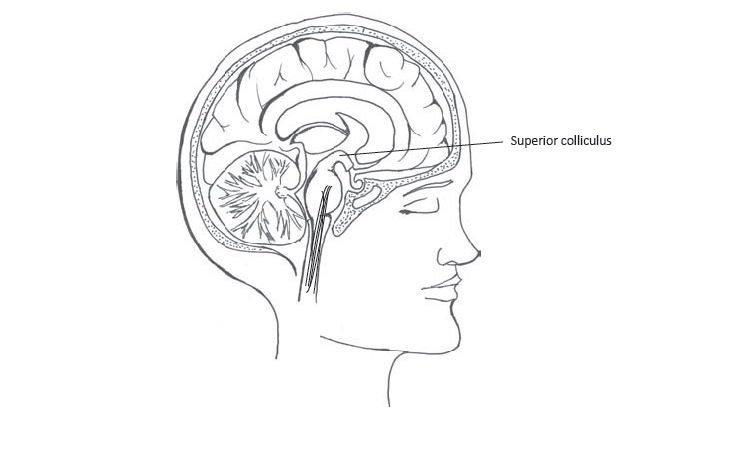
More importantly, our perceptual system must have some method of combining the sensations from the different modes, so that life does not seem like a foreign film badly dubbed into English. To achieve integration, it makes sense that neural signals from the separate sensory channels would be collected in specific areas of the brain, and indeed this seems to be the case. There are areas throughout the midbrain and cortex that respond only to input from multiple sensory channels. One key brain area for this integration work is a part in the midbrain, called the superior colliculus (King and Schnupp, 2000). The superior colliculus receives input about timing and spacing from the different senses, and it is very sensitive to the exact timing and location of inputs. Basically, the superior colliculus is essentially able generate signals that allow us to conclude that sights, sounds, smells, and touches that originate at the exact same time and in the exact same location are part of the same perception.
multisensory enhancement: process through which input from separate sensory modalities combine to produce a perception that is stronger than the individual contribution of the modalities
superior colliculus: an area in the midbrain that plays a key role in integrating the inputs from the different senses into a single coherent perception
Debrief
- Try to think of your own examples of the Gestalt principles of similarity, proximity, figure-ground perception, good continuation, and closure.
- Try to think of some examples when your expectation or the context in which you encountered something influenced the way that you perceived it.
13.4. Attention
At first, you might wonder why the topic of attention is located in a module on Perception. It is true that the topic could appear elsewhere, including in its own module, as it is an important topic in its own right. But it is perhaps the most important precondition for transitioning from sensation to perception, or conscious recognition. In order to recognize something, you must direct attention to it.
You are in class on a super sailorific sunshiny day, and you just cannot keep you mind on the boring lecture being delivered by your professor, Dr. Dronesonandon. Well, at least you don’t have to write an essay.
You can also access this video directly at: https://youtu.be/C-1O2TvnrNE
But back to Dr. D. You struggle to listen, but your mind keeps wandering, first to the activities outside, then to your shopping list and planning your afternoon workout. Before you know it, class is over, and you have not heard one word out of your professor’s mouth in the last 30 minutes. Oops. Many people (not just students) struggle with paying attention. But what is attention, exactly? For the moment, let us define it as the current contents of your consciousness, or what you are thinking about right now. We will need to be a bit more precise later, but this preliminary definition will allow us to start the conversation.
At any given time, you have a virtually limitless amount of possible conscious mental activity available to you. You can consciously perceive any subset of the world surrounding you, can retrieve information from you episodic and semantic memory, and you can think about possible events in the future. We would like you to try a thought experiment. Try to think about ALL of those possible mental activities right now. Didn’t get very far, did you? Most of us would not even know how to start. So, one of the easiest facts to notice about attention is that it is limited. Very limited.
One way to think about attention is as a filter.
There is some information that is important, so we focus on that. Other, unimportant information, then, is filtered out or ignored. But how and when do we filter it, and how do we make the decision that something is important or not? That process is called selective attention, and it was one of the earliest topics about attention that psychologists studied, and their research gave us some of the answers to those questions.
Imagine you are sitting in your dining room watching a TED Talk as background information for a paper in English class, and two people are having a conversation in the next room. You have to focus on your paper and ignore the other voices. We can achieve this filtering on the basis of physical characteristics, and those physical characteristics can make the process easier or more difficult. For example, consider the physical intensity or strength of the stimulus (see Module 12). Suppose the conversation in the other room is extra loud and the TED Talker very quiet? Obviously, that would make it difficult to block out the voices on the TV. Or how about the similarity of the channels of information? If the TED Talker is a high-pitched woman’s voice, and the other conversation between two men’s voices, it is fairly easy to select on the basis of the difference in pitch.
Suppose you are basically successful. You are in one room concentrating on the TED Talk, and focusing so hard that you do not even really hear the other conversation. Or do you? If the conversation between two men suddenly FaceTimed in a woman, do you think you would notice? Most people would (Broadbent, 1958). So we are filtering based on physical characteristics, but not fully blocking out the ignored channel. We can detect changes in those physical characteristics. But there is something missing in our understanding so far. For example, if the people speaking in the other room changes from English to German, do you think you would notice that? Most people do not (Cherry, 1953). If you maintain focus on the task at hand (the TED Talk), you can monitor for changes in physical characteristics, but you cannot hear what was being said. Or can you? What if they said your name? Do you think you would notice that? Most people do. And there is other personally meaningful information that people can often hear from the non-attended information.
How do we make sense out of these somewhat confusing findings? We notice the addition of a woman’s voice, we do not notice a change from one language to another, but we do notice our own name. It is clear that we are not simply filtering out the unwanted information, but monitoring it in the background, ready to select for different kinds of characteristics. Perhaps the best explanation comes from the multimode model of selective attention (Johnston & Heinz, 1978). According to this model, we can change the type of information we monitor in the filtered-out information based on the demands of what we are trying to do. At nearly all times, we can monitor simple physical characteristics, such as pitch or loudness. Suppose you were aware that the other-room conversation might get interesting (for example, you are expecting it to turn to some juicy gossip). You can monitor for that information in the background so if the conversation gets interesting you might notice it. And there is some information that you are basically always on the lookout for, your name, for example.
Now that you realize that we can at least extract some information from non-attended channels, you might wonder if we can actively pay attention to it. In other words, can we pay attention to two separate channels at the same time? This is called divided attention, and we commonly refer to it as multitasking. And here the research results are a bit more straightforward. Are people good at multitasking?
No.
It is true that research has found that some people can learn to perform two tasks at the same time—in this case taking dictation while reading unrelated text (Spelke et al., 1976). In order to be successful, though, they were trained for 17 weeks, 5 days per week for an hour on the two specific tasks. That is a far cry from trying to read psychology while posting on Instagram without any specific training. It actually appears that in most cases, people are not truly multi-tasking, but task switching (moving back and forth rapidly between tasks). In both the simultaneous case and the task-switching case, however, it appears that performance suffers on both, at least for most people (Hirst, Spelke, & Neisser, 1978; Monsell, 2003). So, if you want to make good Instagram posts, you had better stop distracting yourself with psychology.
divided attention: the process of focusing on more than one stimulus or task at the same time, often called multitasking
multimode model of selective attention: a model of attention that suggests that our attentional filter is flexible; we can monitor the contents of filtered-out information depending on tasks demands
selective attention: the process of focusing on one stimulus or tasks and screening out others
task switching: moving back-and-forth rapidly between tasks
